
Ivan Smirnov, PhD
computational social scientist
Ivan Smirnov is a computational social scientist exploring the evolving relationship between technology and society. His current focus is on Generative AI: he both conducts research on GenAI and employs GenAI to conduct research. He is particularly interested in exploring AI‘s potential role in improving doctoral students’ wellbeing and helping them navigate the hidden curriculum in academia.
Beyond his research, Ivan is deeply committed to empowering the next generation of scientists through teaching, social entrepreneurship, and the development of open educational resources, such as the open course Getting Started with Generative AI in Research.
Dr Smirnov is the AI Lead in Research and Researcher Training at the Graduate Research School, University of Technology Sydney. He is also an External Faculty Member at the Complexity Science Hub, Vienna. Previously, he served as an Assistant Professor at the University of Mannheim and led a research group at the Higher School of Economics, Moscow.
His research has been regularly presented at flagship conferences in his field, such as IC2S2 and ICWSM; published in leading journals, including Proceedings of the National Academy of Sciences, EPJ Data Science, PNAS Nexus, and Royal Society Open Science; and featured in major Australian and international media outlets: ABC TV, MIT Technology Review, The Times, and Nature.
Email: ivan@smirnov.au
Curriculum Vitae
Toxic comments are associated with reduced activity of volunteer editors on Wikipedia
For a project entirely relying on volunteer work, Wikipedia's success is remarkable. It is the fourth most popular website on the internet, behind only such giants as Google, YouTube and Facebook. Every day, millions of people worldwide use it for quick fact-checks or in-depth research. And what happens to Wikipedia matters beyond the platform itself because of its central role in online information infrastructure. Given Wikipedia’s encyclopedic status, many do not suspect that discussions between editors could be quite heated. For example, one editor wrote to another: “i will find u in real life and slit your throat”. Our research reveals not just the presence of toxicity on Wikipedia, but also its significant impact on the editors. This could impact the quality of Wikipedia content and threaten the long-term viability of the project.
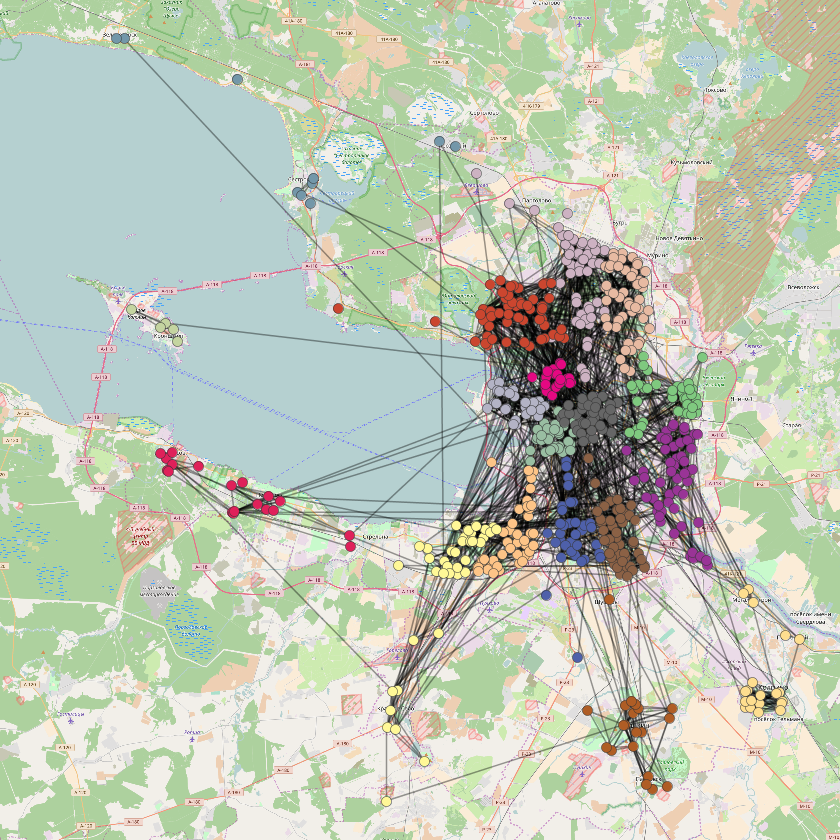
Schools are segregated by educational outcomes in the digital space
While there are many studies on the friendship between students, most of them focus on students from a single educational institution, i.e. study friendship ties within one school or one university. As a result, little is known about social connections between students from different schools. In this paper, I have used digital traces to investigate interschool friendship on a scale of the whole city. I have analyzed data on 37,000 students from 590 schools and their friendship links on VK and have found that students from similar performing schools tend to become online friends. One might assume that this is a trivial consequence of the geographical segregation of schools. However, by adding data on school locations and apartment prices, I was able to show that segregation in the digital space is in fact much stronger than geographical segregation.
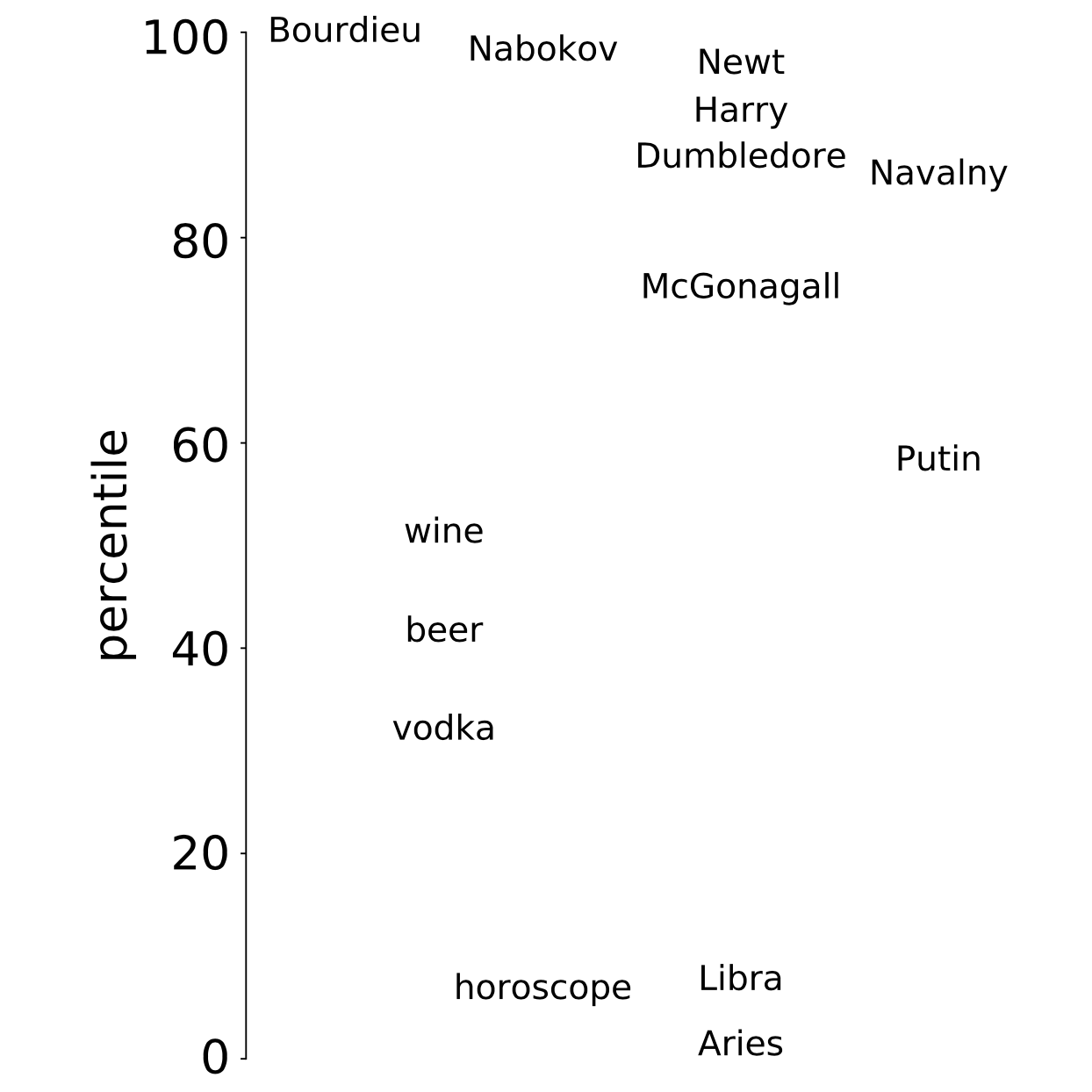
Predicting academic performance from social media posts
In this paper, I have built a model to predict the academic performance of students from their posts on social media. I have combined unsupervised learning of word embeddings on a large corpus of social media posts with a supervised model trained on data from a nationally representative sample of young adults. This data set contains the academic performance of students measured by a standardized test as well as information on their public activity on social media. I have used a continuous-vocabulary approach that allowed achieving high accuracy using a relatively small training data set. It also allows computing interpretable scores for millions of words that are fun to explore!
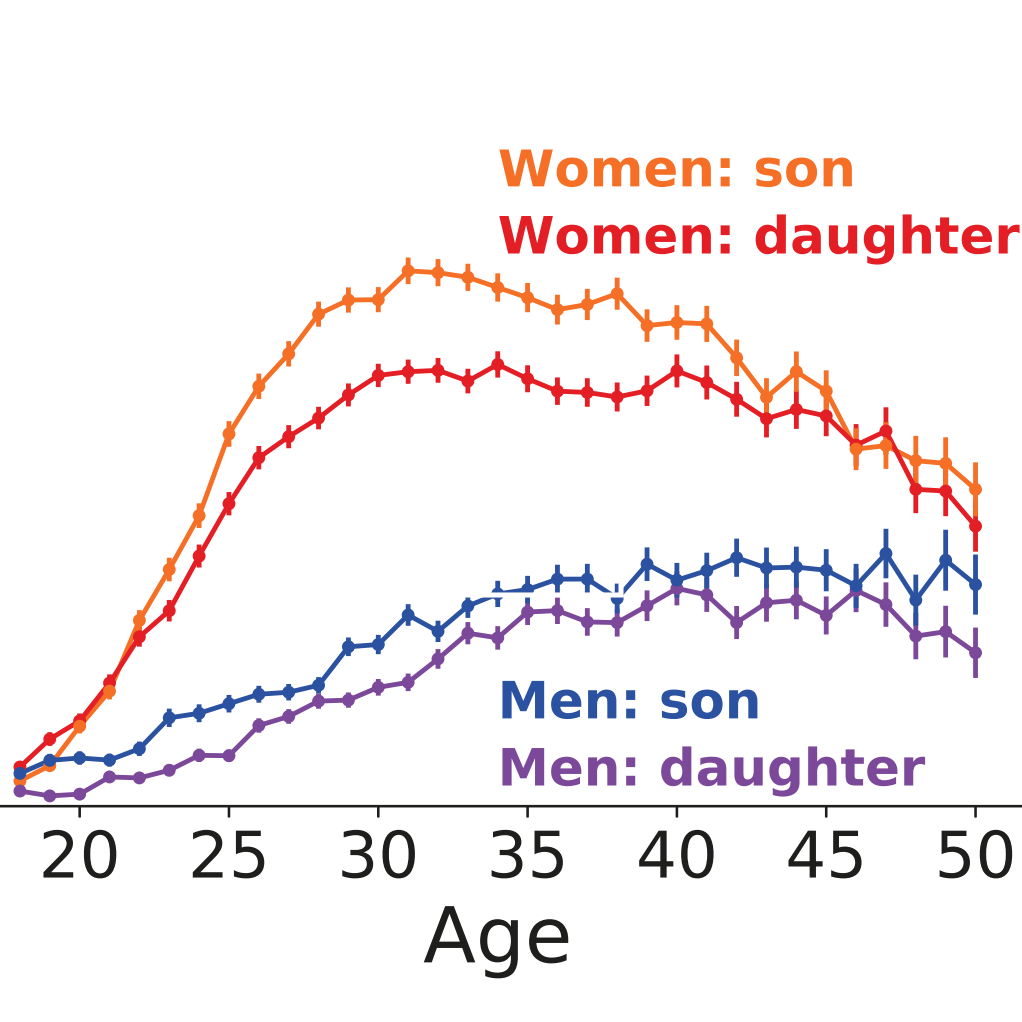
Parents mention sons more often than daughters on social media
Parents' preference for sons is a well-known phenomenon that manifests in various forms from sex-selective abortions to higher investments in sons. In this paper, we used public posts made by 635,665 users on a popular Russian social networking site, to investigate public mentions of daughters and sons on social media. We find that both men and women mention sons more often than daughters in their posts. We also find that posts featuring sons receive more “likes” on average. Our results indicate that girls are underrepresented in parents’ digital narratives about their children. Previous studies have shown female characters are underrepresented in children’s books, textbooks, movies, and on Wikipedia. Gender imbalance in public posts may send yet another message that girls are less important and interesting than boys and deserve less attention, thus presenting an invisible obstacle to gender equality.
- What is Computational Social Science really?
- Common pitfalls in Computational Social Science
- How to write a Computational Social Science paper
- How to Publish a Computational Social Science Paper
- Common Pitfalls in Quantitative Research
- How (not) to become successful in academia RU
- On using digital traces to study wellbeing of students RU
- On using digital traces to study inequality in education RU
- What makes a good compuational social science paper RU